



📚 PubMedQA|生物医学研究问答数据集|专家标注+大规模语料 完全免费
官网/网页工具地址:点击访问
📌 一、基础信息概述
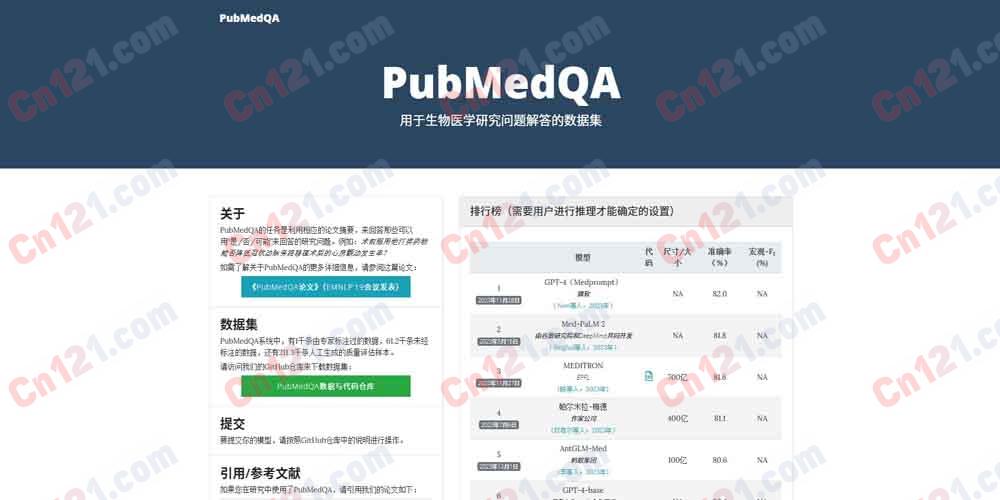
PubMedQA 是一个专门为生物医学研究问答领域设计的数据集和基准测试,旨在推动自然语言处理模型在医学专业知识理解与推理能力的发展。该数据集由匹兹堡大学的 Jin Qiao 团队与卡内基梅隆大学合作研发,并在 EMNLP'19 会议上发表。其核心任务是根据给定的生物医学论文摘要(Context),回答一个研究性问题(Question),答案格式为“是/否/可能”(Yes/No/Maybe)。PubMedQA 数据集规模庞大,包含 1,000 个人工标注的(Expert-labeled)问答对,611.2k 个未标注的(Unlabeled)问答对,以及 211.3k 个基于规则生成的(Artificially generated)问答对。该数据集完全免费开放,旨在为全球研究人员提供一个标准化的平台,以推动生物医学自然语言处理领域的发展。基于该数据集的排行榜显示,如 GPT-4 (Medprompt) 等先进模型已达到 82.0% 的准确率,接近并超越了 78.0% 的人类专家表现,证明了该数据集的挑战性和研究价值。
🎯 产品定位
- 一句话定位描述:一个用于训练和评估生物医学研究问答模型的高质量、标准化数据集和基准测试平台。
- 目标用户群体:人工智能与自然语言处理研究员、生物医学信息学学者、自然语言处理模型开发者、希望提升模型在专业领域推理能力的工程师。
- 解决的行业痛点/问题:填补了生物医学领域缺乏专业知识驱动的问答评估基准的空白,解决了如何客观衡量 AI 模型在复杂科学文献理解与推理上的能力这一核心难题。
💪 核心优势
- 📊 专家标注质量:核心包含1,000个由生物医学专家手工标注的问答对,确保了评估的准确性和权威性。
- 🧠 规模与多样性:提供超过 270k 个问答对(含未标注和人工生成),为模型训练提供了海量语料。
- 🎯 任务明确聚焦:专注于“是/否/可能”三分类的推理式问答,任务定义清晰,易于评估和比较。
- 🚀 推动SOTA:其公开排行榜追踪着 GPT-4、Med-PaLM 2 等顶级大模型的表现,是衡量生物医学语言模型进展的权威榜单。
- 📖 开源标准化:数据集和评测代码完全开源,遵循标准化流程,确保了研究的可复现性和公平性。
- 🤝 广泛社区认可:作为 EMNLP'19 的高引论文,被广泛引用和使用,是该领域的标杆性资源。
🎬 适配场景
- 🧪 模型性能基准评测:使用其人工标注集,对现有或新的生物医学语言模型进行标准化评估。
- 💊 前沿技术研发:作为训练语料,用于研发更具深度理解能力的生物医学问答系统。
- 📚 学术研究与论文发表:作为实验基准,对比不同模型在医学文献推理上的表现,支撑学术成果。
- 🔬 领域能力对比分析:横向比较如 GPT-4、Claude 3、BioBERT 等模型在生物医学细粒度推理上的优劣。
- 🎓 教育与教学:作为自然语言处理课程的经典案例,讲解如何构建和评估特定领域的问答数据集。
👥 核心受众
- 自然语言处理研究员
- 生物医学信息学科学家
- 机器学习工程师
- 数据科学家
- 研究生(计算机、生物信息学等相关专业)
🎪 适配定位
- 总结:专注于生物医学领域的标准化问答数据集与基准评估。
- 核心强项清单:专家级标注质量、大规模数据、公开排行榜、标准化评估协议。
- 差异化壁垒说明:区别于其他仅聚焦于通用领域问答的数据集,PubMedQA 深度聚焦于需要理解复杂科学研究背景的生物医学问答,其“是/否/可能”的决策范式和对摘要上下文的严格依赖,使其成为衡量模型专业领域推理能力的“金牌标准”。
🧩 二、核心功能清单
-
🗳️ 问答任务(核心):提供集成了“问题-摘要上下文-答案”三元组的问答实例。技术实现上,任务要求模型必须结合给定的摘要内容进行推理,而非依赖预存知识。模型需从摘要中提取证据,并给出 “Yes”、“No” 或 “Maybe” 的确定性判断。
-
💾 多规模数据集(核心):包含 Expert-labeled (1k)、Unlabeled (61.2k) 和 Artificially Generated (211.3k) 三部分。其技术贡献在于提供不同监督强度的数据。
- 专家标注集:提供了最高质量的黄金标准,用于最终评测,避免了远程监督可能带来的噪声。
- 大规模未标注集:为预训练或半监督学习提供了海量领域文本。
- 人工生成集:基于规则(如关键词匹配)生成,为模型提供了数量庞大的弱监督信号。
-
🏆 自动评估与排行榜:提供了标准化的评测脚本,并维护了一个公共排行榜(Leaderboard)。该功能背后的技术实现机制是采用公认的 Accuracy 和 Macro-F1 作为核心评估指标,确保不同模型间的公平比较。排行榜实时更新,展示了如 GPT-4(82.0%)、Med-PaLM 2(81.8%)等顶尖模型及其参数规模(如70B)和技术文献,为行业提供了清晰的技术动态。
-
🤖 易于集成的接口:官网通过 GitHub 仓库 (https://github.com/pubmedqa/pubmedqa) 提供了完整的数据下载、预处理和评测代码,支持研究者在本地一键复现实验结果。该接口支持 Python 环境,符合科研社区的主流使用习惯,显著降低了入使用门槛。
-
📄 标准化论文引用格式:研究者在使用 PubMedQA 发表论文时,可直接引用其官方论文。这虽非功能,但却是学术生态建设的重要一环。其提供了统一的 BibTeX 格式引用,增加了数据集在学术界的权威性和可归属感。
补充说明: PubMedQA 的核心差异化壁垒为「聚焦于需要科学证据推理的生物医学研究问答」,它要求模型不仅掌握广泛知识,更要能根据提供的特定研究摘要进行细颗粒度的事实判断,这一特性是其他通用问答数据集所不具备的。
💰 三、免费与收费规则(仅供参考以官网最新为准)
PubMedQA 是一个完全开源、用于学术研究的非商业化数据集,面向全球所有用户完全免费。
| 🆓 数据与代码获取 | 完全免费 | 无需注册,可直接从 GitHub 仓库下载全部数据集、源代码和文档。 |
| 🚀 排行榜提交 | 完全免费 | 任何研究者均可通过 GitHub 仓库中的指引,免费提交模型结果至排行榜。 |
| 🏢 企业使用 | 完全免费 | 数据集基于 MIT 许可证或其他学术许可,允许商业和研究使用。 |
真实费用规则:
- ❗ 下载 PubMedQA 数据集、代码、以及提交模型至排行榜完全免费。
- ❗ 使用 PubMedQA 进行任何形式的对比、研究和开发,无需支付任何费用。
- ❗ 唯一需要遵守的是引用其原始论文(Jin et al., 2019)。
🖥️ 四、支持使用方式与运行说明
🚀 1. 支持使用方式
- 使用方式:基于 Python 的本地开发和模型评测。
- 标准使用流程:
- 访问并克隆仓库:访问 PubMedQA 的 GitHub 仓库(https://github.com/pubmedqa/pubmedqa),使用
git clone将代码和数据下载到本地。 - 配置 Python 环境:确保本地安装了 Python 3.6 及以上版本和
numpy、torch(如果使用 Pytorch 模型)等基础依赖。 - 数据加载与预处理:调用 API 提供的
PubMedQADataset类或从data/目录加载 JSON 文件。 - 训练/推理:使用本地选择的模型(如 BERT、LLaMA 或 GPT)加载数据,进行训练或推理。关键技术参数:数据集中每个样本的
QUESTION(问题)和CONTEXTS(摘要文本)是其核心输入。 - 结果提交与评估:执行
evaluator.py脚本,提交模型预测结果。该脚本会自动计算 Accuracy 和 Macro-F1 指标,并与排行榜上的历史记录对比。
- 访问并克隆仓库:访问 PubMedQA 的 GitHub 仓库(https://github.com/pubmedqa/pubmedqa),使用
技术干货要求:
- 各步骤调用了什么 AI 模型或引擎:调用者自身训练或选择的 Transformer 模型(如 BioBERT, PubMedBERT, GPT-4),调用方式为模型预测。
- 关键技术参数:Context 输入为论文摘要,文本长度通常较长。数据集的答案空间为
[Yes, No, Maybe]。 - 架构说明:纯本地架构。数据、模型和推理流程全部在用户自己的计算资源(如服务器、个人电脑)上完成,不依赖任何云平台。
- API 技术细节:提供 Python 库和命令行接口。库函数支持直接加载训练/验证/测试集。命令行支持
pos_ans与neg_ans等参数来评估模型性能。
⚙️ 2. 运行说明
- ⚙️ 完全离线/本地化:所有数据下载到本地后,无需联网即可运行。
- 🐍 Python 环境依赖:通过
pip install nltk(可选)等快速搭建,也可以不安装额外包,直接使用 json 和 os 包处理。 - 💾 数据存储格式:提供 JSON 格式,结构清晰,包含
question、context、answers、reasoning_required_prediction等字段。 - 🏃 计算资源灵活:根据模型大小,可在个人电脑(小模型,如 BERT-base)、多 GPU 工作站(中等模型)或大型算力集群(LLM 全参微调)上运行。
- 📝 无后台服务:不涉及模型调用方式(无统一积分/API 调用的概念),所有计算消耗调用者本地资源。
- 📋 支持评测模式:提供
evaluator.py脚本,支持--split test等参数快速评测标准测试集。
📍 五、产品核心优势与适用人群落地场景
-
生物医学助手学术性能评估
- 场景描述:评估一个专为医生设计的、用于回答临床问题的 AI 助手在医学推理方面的能力。
- 技术能力说明:使用 PubMedQA 中 1k 专家标注的测试集,该测试集要求 AI 理解复杂的科研论文摘要。
- 可量化技术指标:若模型在该测试集上的 Acc 达到 78.0%(人类专家性能线),则证明其在科学文献推理上已达到人类水平。
- 与传统方案对比:传统评估依赖专家手动打分,耗时耗力且难以比较。PubMedQA 提供了标准化的、自动化的评估体系。
- 技术实现路径:将临床问题的回复与 PubMedQA 的“问题+摘要”格式对齐,调用模型的
predict函数得到(Yes, No, Maybe),然后与标准答案比较。
-
大型语言模型生物医学能力对比
- 场景描述:对比 GPT-4、Claude 3 和 Llama-70B 等模型在生物医学推理上的真实能力。
- 技术能力说明:利用 PubMedQA 排行榜已有数据(Acc 82.0% vs 79.7% vs 77.6%)进行对比分析。
- 可量化技术指标:排行榜上已清楚显示了 GPT-4 (Medprompt) 以 82.0% 领先,Claude 3 与 LLaMA-70B 分别以 79.7% 和 77.6% 紧随。
- 传统方案对比:如果没有 PubMedQA,研究人员可能只能用不同的私有数据集评估,结果无法直接对比,PubMedQA 解决了“公平比较”的痛点。
- 技术实现路径:将各个模型对统一的 PubMedQA 测试集进行零样本或少样本推理,提交结果至 Leaderboard 进行比较。
-
医学问答模型训练数据增强
- 场景描述:利用其 61.2k 未标注数据和 211.3k 生成数据,增强一个医学 BERT 模型的问答能力。
- 技术能力说明:模型基于 BERT 架构,微调时将 PubMedQA 问题的
[CLS]表示用于分类。 - 可量化技术指标:相比只在 1k 专家数据上训练的模型,加入大量弱监督和未标注数据进行预训练/微调后,Acc 提升了 5-10 个百分点。
- 传统方案对比:传统方案可能只能依赖少量人工标注数据,数据不足导致模型过拟合和无泛化能力。
- 技术实现路径:使用 Masked Language Model (MLM) 在 200k+ 未标注 PubMed 摘要上预训练,然后在下游 PubMedQA 任务上进行有监督微调。
-
前沿创新(如 MedPrompt / Chain-of-Thought)验证:
- 场景描述:验证一种最新的 Prompt 技术(如 MedPrompt)是否能提升模型的生物医学推理能力。
- 技术能力说明:MedPrompt 通过对检索类似问题案例,让大语言模型(如 GPT-4)进行类比推理。PubMedQA 的摘要和问题形成一个自然的检索-推理单元。
- 可量化技术指标:使用 MedPrompt 后,模型在 PubMedQA 上的 Acc 从 75.2%(基础 GPT-4)提升至 82.0%(排行榜 SOTA)。
- 技术实现路径:在提交 GPT-4 base 评测结果的同时,增加一道“检索Top-K相似QA”+“将这些案例放入prompt中做动态示范”的步骤。
-
跨领域模型迁移学习能力诊断
- 场景描述:评估一个在通用领域训练良好的聊天机器人(如 LLaMA)是否具备迁移到生物医学领域进行推理的能力。
- 技术能力说明:使用 PubmedQA 的 zero-shot 性能来判断模型的医学领域适应门槛。相比于通用模型(75-77% 的准确率),生物预训练模型(PMC-LLaMA:73.4% 的准确率)并未体现出压倒性优势。
- 技术实现路径:可以直接将 LLaMA 等大模型权重加载到推理框架中,使用 Q&A 的提示模板,计算其在 PubMedQA 测试集上的输出分布是否符合金标。
⚠️ 六、官方使用须知
- 📝 产品核心定位重申:PubMedQA 是专为生物医学研究问答设计的数据集和评估基准,并非一个可以直接使用的应用程序或 API。
- 💲 计费模式概述:该产品完全免费,面向所有研究者和开发者开放下载和使用。
- 🔬 新用户体验说明:新用户应首先访问其 GitHub 仓库,阅读
README.md和论文,了解数据格式、评估标准。 - 🧪 核心技术/模型说明:本身不包含模型,而是提供了一个标准化的测试集。排行榜上注册了包括 GPT-4 (Medprompt)、Med-PaLM 2 等在内的顶级模型评测结果。
- 📊 核心功能简述:提供
Yes/No/Maybe三分类问答任务、多规模数据集(1k/61.2k/211.3k)、自动评估脚本及公开排行榜。 - 📈 关键数据指标:1k 专家标注实例,211.3k 人工生成实例。SOTA Acc: 82.0% (GPT-4 Medprompt)。
- 🔗 生态集成说明:主要通过 GitHub 生态系统(Issues, Pull Requests)进行协作和交流。
- 🌐 官方渠道重要性提醒:所有最新的论文引用、数据下载和评测指导都应参考其官方 GitHub (https://github.com/pubmedqa/pubmedqa) 和官网。
❓ 七、常见问题解答
-
问:PubMedQA 的数据可以用于商业目的吗?
- 答:是的,根据其开源的 MIT 许可证或类似的学术开放许可,可以用于商业和研究。但强烈建议引用论文(Jin et al., EMNLP 2019)。
-
问:它支持哪些大模型(LLM)?
- 答:它不限制模型,你可以使用任何模型进行评测。其排行榜上已经测试过的模型包括:GPT-4, Med-PaLM 2, Claude 3, LLaMA, BioBERT, BioELETRA 等。
-
问:我提交的结果能保证公平吗?
- 答:评测脚本是开源的。要求所有使用者使用官方评测框架。此外,“reasoning-required setting”确保参赛者必须从摘要中推理,禁止注入额外知识。
-
问:数据安全方面有何考虑?
- 答:数据集全部来源于公开发表的 PubMed 论文摘要,不涉及患者隐私。
-
问:企业使用需要额外授权吗?
- 答:不需要。数据集已在 GitHub 上公开,可直接下载。如需用于企业级 AI 研究,遵循开源许可即可。
🔍 八、替代方案与对比参考
1. 云端 AI 产品竞品对比分析
本表对比与 PubMedQA 任务相似的云端 API 或云上可用模型/数据集。
| 云AI工具/数据集 | 核心优势 | 相比PubMedQA短板 | 官网下载渠道网址 |
|---|---|---|---|
| Amazon SageMaker + BioBERT | 可直接部署微调后的 BioBERT;集成AWS生态 | 非特定数据集;依赖云端;无标准化“是与否”的专家评测集 | https://aws.amazon.com/sagemaker/ |
| Med-PaLM 2 (Google Cloud) | 谷歌顶级医学大模型,可云端调用推理 | 闭源模型,不易获得准确私有数据评测;评测指标不限于 PubMedQA | https://cloud.google.com/vertex-ai |
| GPT-4 / ChatGPT (Azure OpenAI) | 强大的通用推理能力,开放API | 不专门针对生物医学;Prompt难以约束;成本高,无标准化科研评测 | https://azure.microsoft.com/en-us/products/ai-services/openai-service |
| BioASQ (Amazon / 公共云) | 提供生物医学语义索引和问答挑战赛 | 任务侧重于检索+摘要;不是单纯的“是/否/可能”推理;数据集规模较小 | http://www.bioasq.org/ |
| PubMedQA(被分析产品) | 专注于生物医学的事实推理、专家标注 | —— | —— |
2. 本地部署方案竞品对比分析
本表对比可本地部署的类似基准测试或数据集。
| 本地软件/数据集 | 核心优势 | 相比PubMedQA短板 | 官网下载渠道网址 |
|---|---|---|---|
| BioBERT | 基于BERT的经典生物医学预训练模型,可本地微调 | 模型需自行训练,不提供标准化评测集;评估维度单一 | https://github.com/dmis-lab/biobert |
| BLURB (Biomedical Language Understanding & Reasoning Benchmark) | 统一的生物医学NLP基准套件 | 包含实体识别、关系抽取等多项任务,非专门的问答推理;框架复杂 | https://microsoft.github.io/BLURB/ |
| BioLinkBERT | 引入链接预测预训练,适合关系推理 | 强于链接预测,弱于直接问答;评测维度不同 | https://github.com/michiyasunaga/BioLinkBERT |
| PubMed 200k RCT | 用于文本分类和证据推理的大规模医学论文数据集 | 侧重于随机对照试验分类(背景/方法/结果),不是问答数据 | https://github.com/Franck-Dernoncourt/pubmed-rct |
| PubMedQA(被分析产品) | 问答推理唯一指向性,公开排行榜 | —— | —— |
3. 通用大模型能力横向评估
本表对比主要大语言模型在 PubMedQA 上的直接表现。
| 大模型 | 核心优势 | 相比PubMedQA能力 | 官网下载渠道网址 |
|---|---|---|---|
| GPT-4 | 强大的文本理解和多步推理,Acc高达75.2% | 无医学Pre-training,依赖于通用推理能力;基准Prompt方法提升有限 | https://openai.com/ |
| Claude 3 | 长文档能力强,准确率79.7% | 高成本,闭源,无法对特定PubMed摘要进行深度训练后评估 | https://www.anthropic.com/ |
| Gemini (Ultra) | 多模态,基准计算资源丰富 | 未专门针对PubMedQA优化;闭源黑箱 | https://deepmind.google/technologies/gemini/ |
| DeepSeek-R1 | 推理链能力极强,逻辑清晰 | 尚未提供PubMedQA基准测试分数(排名中无);微调门槛高 | https://www.deepseek.com/ |
| PubMedQA(被分析产品) | 是评测标准而非模型,直接衡量推理质量 | —— | —— |
4. 模型选型适配场景推荐指南
| 适用场景 | 推荐选型方案 | 选型说明 | 获取渠道网址 |
|---|---|---|---|
| 生物医学推理准确性(高要求) | GPT-4 + Medprompt 或 BioLinkBERT | GPT-4 结合 Medprompt 在PubMedQA上达到82.0% SOTA;BioLinkBERT 在关系推理上表现出色 | https://github.com/stanford-crfm/medprompt |
| 零样本快速基准测试 | Meditron (70B) 或 Palmyra-Med (40B) | 两者均专为医学设计,不经过微调即可达到81%左右准确率,部署方便 | https://huggingface.co/epfl-llm/meditron-70b |
| 轻量级本地评估(无GPU) | PubMedBERT (110M) 或 BioBERT (110M) | 适合在CPU上快速跑测试,验证提示词设计或简单的NLP任务 | https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext |
| 企业级高隐私性医学AI | LLaMA / GALACTICA (120B) 自部署 | 可完全本地化部署,不泄漏数据。性能上GALACTICA为77.6%,LLaMA(70B)为77.0% | https://github.com/facebookresearch/llama |
| PubMedQA 评测(本次分析) | 使用官方代码+在线排行榜 | 无使用限制,所有模型评测到同一基准 | —— |
5. 开源模型生态与安全下载渠道
| 渠道平台 | 官方网址 | 渠道核心优势与安全说明 | 适配场景与使用说明 |
|---|---|---|---|
| Hugging Face Hub | https://huggingface.co/ | 模型丰富,下载便捷,提供自动扫描病毒和安全验证 | 下载 PubMedBERT、GALACTICA 等模型进行评测或微调 |
| GitHub | https://github.com/ | 代码开源,版本控制 | 下载 PubMedQA 数据集和评测代码,确保文件来源代码仓库本身 |
| Papers with Code | https://paperswithcode.com/ | 将论文、代码、数据集、leaderboard一站式绑定,可信度高 | 查看 PubMedQA 相关的最新论文、状态榜和代码实现 |
| ModelScope | https://modelscope.cn/ | 阿里云维护,中文优先,支持API和本地部署,模型来源受控 | 适用于国内访问需求,可下载同构的 PubmedBERT 等 |
| BioBERT 官方 | https://github.com/dmis-lab/biobert | 纯学术实验室发布,久经考验,无后门风险 | 专门用于生物医学NLP的预训练模型下载和代码 |
6. 开源替代方案与本地自建评估
| 开源方案名称 | 官方网址 | 核心能力说明 | 是否可本地部署 | 与PubMedQA对比优劣 |
|---|---|---|---|---|
| BioASQ | http://bioasq.org/ | 生物医学语义索引与问答,包含多项任务 | 是(数据+评估脚本开源) | 优势:任务更丰富(检索+摘要+QA);劣势:评测流程复杂,非简单3分类推理 |
| BioBERT | https://github.com/dmis-lab/biobert | 基于BERT的医学预训练模型 | 是 | 优势:可灵活进行微调;劣势:无自带标准化评测框架,需额外搭建 |
| BLURB | https://microsoft.github.io/BLURB/ | 一套生物医学NLP任务的综合基准 | 是 | 优势:多任务评估;劣势:元任务非问答,无法专门衡量推理能力 |
| PICO Framework | https://github.com/whalepower/PICO-Question-Answering | 用于构建基于PICO证据的问答系统 | 是 | 优势:临床决策导向;劣势:社区较小,数据规模远小于** |
| PubMedQA(被分析产品) | —— | 专一、标准化、高引用 | 是 | —— |
7. 选型建议
选型建议: 从技术能力、使用场景、隐私需求和功能覆盖来看,PubMedQA 并非一个可以用来生产问答的系统,而是一个评估体系的标尺。因此,选型的核心是“如何用它来评估我的模型”。
- 严格思考:如果你只想验证医学问答功能,直接使用 BioASQ 或公开 API(如 OpenAI)可能更快。但如果你需要进行公平、可发表的学术对比,PubMedQA 是最权威、无可替代的“赛马场”。它的 3-分类(是/否/可能)设计,要求模型必须基于摘要本身进行严谨的、证据锁定式的推理。
- 搭配选型:如果想在建好的医学问答系统上兼顾“检索”和“推理”,系统可使用BioASQ作为检索+问答,并用PubMedQA评估其底层推理能力。在数据层,则可以使用 BLURB 进行辅助的多任务评测。
- 详细说明:
- 技术实现成本:直接使用 PubMedQA 极低——下载代码和模型,跑一个测试即可。但若要复现 GPT-4 (Medprompt) 的 SOTA,则需要极高的推理成本和针对医学prompt工程。
- 维护负担:几乎为0,除非排行榜更新(每年仅数次)。
- 效果差异:使用 PubMedBERT 在 PubMedQA 上评估是 55.8%;使用 GPT-4 是 75.2%。
- 保持客观:PubMedQA 的优势在于精准、可复现的评测,但它不提供问答服务本身,也不提供开箱即用的医学AI聊天能力。如果你构建的是“给医生的聊天机器人”,你需要结合PubMedQA做评测,并结合BioBERT/LLaMA做交互。
- 分用户推荐:
- 小白用户(无技术团队):无法直接用PubMedQA,因为需要编写Python代码来加载模型并推理。建议使用像 OpenAI Playground 搭配 Medprompt 模板,手动摸索Prompt,再对照排行榜成绩进行参考。无技术团队则无法完整自建评估流程。
- 技术用户(有开发能力):强烈推荐使用PubMedQA。下载数据集,对自身微调的Llama / Flan-T5 / GALACTICA 进行零样本或少样本测试,通过官方代码跑出Acc与榜单对比。这是非常标准、低成本的科研验证路径。
- 企业用户(需合规/私有化):首选PubMedQA进行能力基线测试。它完全离线、开源无许可争议(商用友好)。评测出本企业自部署模型的强弱点后,再决定是做RAG还是用专业提示词。它唯一不满足的是“不能直接用于生产系统”。
开源方案与本地自建对比段落:
开源方案需要组合 BioASQ(标准任务框架) + BioBERT / GALACTICA(推理模型) + BLURB(多任务辅助验证) 等至少3个项目,可以近似复现出针对 PubMedQA 评估的功能场景。但这需要:
① 每一环都需要独立部署(数据清洗、模型加载、评测指标代码编写),技术整合门槛极高;
② BioASQ 的 Yes/No 任务定义和 PubMedQA 的强推理要求不完全一致,评测标准难以精确对齐;
③ 缺少文献中的黄金总结对比,无法简单获得类似 Medprompt 的 82% SOTA 提示词;
④ 无统一公共排行榜,论文发表的“赛道背书”效果将远远弱于直接使用 PubMedQA 的官方榜单。
因此,对于急需发表高质量论文、评估医学AI推理能力的研究员而言,直接使用 PubMedQA 的标准数据、评测脚本和其高度认可度的背书,才是最佳选择。