



🧩 scikit-learn|Python 机器学习库|分类/回归/聚类/降维/模型选择/预处理+统一 API+NumPy/SciPy 底座+BSD 许可 完全开源免费(BSD)
官网/网页工具地址:点击访问
📌 一、基础信息概述
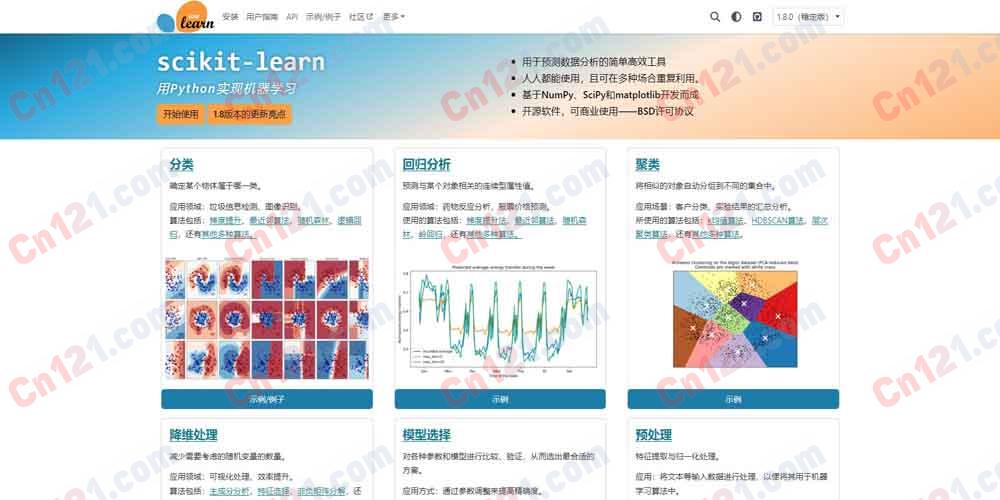
scikit-learn 是 Python 最流行的机器学习库,以「Simple and efficient tools for predictive data analysis」为核心使命。由 David Cournapeau 于 2007 年发起(Google Summer of Code 项目),现由社区志愿者团队维护开发,由 Probabl/INRIA/Chanet/BNP Paribas/Microsoft/Nvidia 等机构资助。scikit-learn 提供统一的 API 设计——所有算法遵循 fit()/predict()/transform() 接口模式,大幅降低学习成本。六大核心模块:分类(识别对象所属类别)、回归(预测连续值属性)、聚类(将相似对象自动分组)、降维(减少随机变量数量)、模型选择(比较/验证/选择参数和模型)、预处理(特征提取和标准化)。基于 NumPy、SciPy 和 matplotlib 构建,采用 BSD 许可。当前稳定版本 v1.8.0(2025 年 12 月),v1.9 正在开发中。被 Spotify、Inria、BNP Paribas 等组织使用。
🎯 产品定位
定位为 Python 机器学习库,以「简单高效的预测数据分析工具」为核心使命。面向数据科学家(快速构建和分析预测模型)、机器学习工程师(算法工程化应用)、科研人员(数据分析和实验)、学生和教育工作者(ML 教学)、任何需要在 Python 中进行预测数据分析的用户。核心解决从零实现 ML 算法需大量时间和专业知识、不同算法之间 API 不统一导致学习成本高、从数据预处理到模型评估缺乏标准化工具链等行业痛点。scikit-learn 的统一 API 设计使所有算法都以 fit(X, y)→predict(X) 方式使用,大幅降低了 ML 的应用门槛。
💪 核心优势
- 🎯 统一 API 设计:所有算法遵循 fit/predict/transform 接口,学习成本极低
- 🧩 六大核心模块:分类/回归/聚类/降维/模型选择/预处理全覆盖
- 🧮 基于 NumPy/SciPy:与 Python 科学生态无缝集成
- ⚡ 高性能实现:核心算法基于 C/Cython 优化,速度快
- 📚 丰富文档:用户指南+API 参考+700+ 示例+70 小时视频
- 🆓 完全开源免费(BSD)
- 🏢 业界验证:Spotify/Inria/BNP Paribas 等使用
- 🤝 社区驱动:开源社区维护,多机构资助
🎬 适配场景
- 🏷️ 分类:垃圾邮件检测/图像识别/客户分类
- 📈 回归:股票价格预测/药物反应/房价预测
- 🗂️ 聚类:客户分群/实验结果分组/数据探索
- 📉 降维:数据可视化/特征选择/噪声约化
- 🔧 模型选择:交叉验证/网格搜索/参数调优
- 🧹 预处理:特征提取/标准化/文本向量化
👥 核心受众
- 数据科学家与数据分析师
- 机器学习工程师
- 科研人员(数据分析和实验)
- 学生和教育工作者(ML 教学)
- 任何需要在 Python 中进行预测分析的用户
- ML 初学者到中级用户
🎪 适配定位
专注 Python 机器学习库赛道。核心强项是「统一 API 设计(所有算法 fit/predict/transform)+ 六大核心模块全覆盖+NumPy/SciPy 底座+C/Cython 高性能+丰富的文档和示例(700+ 示例+70h 视频)+ BSD 开源+社区驱动多机构资助+业界广泛验证」;主打从数据预处理到模型评估的全链路 ML 工具。核心差异化壁垒为「统一 API 设计(fit(X,y)/predict(X)/transform(X),所有算法一致的接口模式,学习成本最低)+ 最完整的传统 ML 算法集(覆盖全部主流分类/回归/聚类/降维/预处理的成熟实现)+ NumPy/SciPy 原生集成(与 Python 数据科学生态无缝兼容)+ BSD 许可+C/Cython 高性能+社区治理成熟」,区别于深度学习框架(PyTorch/TF 侧重神经网络非传统 ML)和其他 ML 库(XGBoost/LightGBM 仅单一算法族)。
🧩 二、核心功能清单
🏷️ 分类(核心)
识别对象所属类别的监督学习算法。覆盖主流分类器:梯度提升(HistGradientBoostingClassifier——直方图加速,适合大数据量)、随机森林(RandomForestClassifier——集成学习经典)、K 近邻(KNeighborsClassifier)、逻辑回归(LogisticRegression)、支持向量机(SVC——核技巧高效实现)、朴素贝叶斯(GaussianNB/MultinomialNB)、决策树(DecisionTreeClassifier)等。统一 fit(X, y) → predict(X) 接口。
📈 回归(核心)
预测连续值的监督学习算法:梯度提升回归(HistGradientBoostingRegressor)、随机森林回归(RandomForestRegressor)、岭回归(Ridge/RidgeCV——L2 正则化)、Lasso(L1 正则化)、K 近邻回归(KNeighborsRegressor)、支持向量回归(SVR)等。
🗂️ 聚类
无监督自动分组算法:k-Means(经典聚类,支持 MiniBatchKMeans 大规模数据)、HDBSCAN(密度聚类,自动确定聚类数)、层次聚类(AgglomerativeClustering)、DBSCAN、高斯混合模型(GaussianMixture)、谱聚类(SpectralClustering)等。
📉 降维
减少特征数量的算法:PCA(主成分分析——最经典的线性降维)、特征选择(SelectKBest/RFE 等)、非负矩阵分解(NMF——适用于非负数据)、t-SNE(高维数据可视化)、Isomap/LocallyLinearEmbedding(流形学习)、TruncatedSVD(稀疏矩阵降维)。
🔧 模型选择
比较、验证和选择模型/参数的交叉工具:GridSearchCV(全网格搜索——遍历参数组合 + 交叉验证)、RandomizedSearchCV(随机搜索——参数分布采样)、cross_val_score(交叉验证评分)、learning_curve/validation_curve(学习曲线/验证曲线)、各类评估指标(accuracy/precision/recall/F1/ROC-AUC/mean_squared_error 等)。
🧹 预处理
特征提取和标准化工具:StandardScaler(标准化——减去均值除以标准差)、MinMaxScaler(归一化——缩放到[0,1]区间)、OneHotEncoder(独热编码——处理类别特征)、LabelEncoder(标签编码)、OrdinalEncoder(序数编码)、KBinsDiscretizer(连续变量离散化)、feature_extraction.text(CountVectorizer/TfidfVectorizer——文本向量化)等。
补充说明:scikit-learn 的核心差异化壁垒为「统一 API 设计(fit(X,y)/predict(X)/transform(X)——所有算法一致的接口范式)+ 最完整的传统 ML 算法集(分类/回归/聚类/降维/预处理全部主流算法的成熟实现)+ NumPy/SciPy 原生集成+ BSD 许可+C/Cython 高性能实现+ 700+ 示例和 70h 视频+社区治理成熟」,区别于深度学习框架和单一算法库。
💰 三、免费与收费规则(仅供参考以官网最新为准)
scikit-learn 完全开源免费。
| 版本类型 | 收费标准 | 权益与限制 |
|---|---|---|
| 🆓 开源版 | 免费(BSD) | 完全开源免费,可商用。 |
真实费用规则:
- BSD 许可证,可商用
pip install scikit-learn即可安装- 所有功能完全免费
- 由社区志愿维护,Probabl/INRIA/MS/Nvidia 等资助
- 所有费用规则以 scikit-learn 官方最新公示为准
🖥️ 四、支持使用方式与运行说明
🚀 1. 支持使用方式
scikit-learn 为本地 Python 库,通过 pip/conda 安装后使用。
标准使用流程: pip install scikit-learn → from sklearn.ensemble import RandomForestClassifier → 创建模型 model = RandomForestClassifier() → model.fit(X_train, y_train) → y_pred = model.predict(X_test) → 评估 accuracy_score(y_test, y_pred)
⚙️ 2. 运行说明
- 🆓 完全开源免费(BSD)
- 🏷️ 分类:GBDT/随机森林/KNN/逻辑回归/SVM
- 📈 回归:GBDT/随机森林/岭/Lasso/KNN
- 🗂️ 聚类:k-Means/HDBSCAN/层次/DBSCAN
- 📉 降维:PCA/特征选择/NMF/t-SNE
- 🔧 模型选择:GridSearchCV/交叉验证
- 🧹 预处理:标准化/归一化/独热编码/文本向量化
- 🧮 基于 NumPy/SciPy/matplotlib
- ⚡ C/Cython 核心优化
- 🏢 社区驱动,多机构资助
- ⚠️ 仅通过 PyPI/conda/GitHub 官方渠道确保代码安全
📍 五、产品核心优势与适用人群落地场景
| 使用场景 | 用户类型 | 传统工具痛点 | scikit-learn 落地优势 |
|---|---|---|---|
| 🏷️ ML 分类/回归建模 | 数据科学家 | 需从零实现算法,代码量大,不同算法接口不统一 | 统一 API:model.fit(X,y) → model.predict(X),数十种分类/回归算法一行切换 |
| 🔧 模型参数调优 | ML 工程师 | 手动调参效率低,缺乏标准化交叉验证工具 | GridSearchCV 自动遍历参数组合+交叉验证,RandomizedSearchCV 大数据量高效搜索 |
| 🧹 数据预处理 | 数据分析师 | 特征标准化/归一化/编码需手动计算或独立工具 | StandardScaler/OneHotEncoder/CountVectorizer 等统一 fit-transform 接口 |
| 🗂️ 客户分群/探索 | 业务分析师 | 需要快速对数据分组但不了解聚类算法实现 | KMeans/HDBSCAN 等聚类算法 fit_predict 一行完成无监督分组 |
| 📉 高维数据可视化 | 研究人员 | 高维数据难以直接观察规律 | PCA/t-SNE 降维到 2D/3D 后直接用 matplotlib 可视化 |
⚠️ 六、官方使用须知
- scikit-learn 核心定位为 Python 最流行的机器学习库。
- 2007 年由 David Cournapeau 发起,社区志愿维护。
- 统一 API 设计:所有算法
fit(X,y)/predict(X)/transform(X)。 - 六大模块:分类/回归/聚类/降维/模型选择/预处理。
- 基于 NumPy、SciPy 和 matplotlib 构建。
- 核心算法基于 C/Cython 优化实现。
- 当前版本 v1.8.0(2025 年 12 月),v1.9 开发中。
- BSD 许可,完全开源免费,可商用。
- Probabl/INRIA/Chanet/BNP Paribas/MS/Nvidia 等资助。
- 仅通过 PyPI/conda/GitHub 官方渠道确保代码安全。
❓ 七、常见问题解答
| 问题分类 | 具体问题 | 官方解答 |
|---|---|---|
| 🧩 产品类 | scikit-learn 是什么? | Python 最流行的机器学习库,提供统一 API 的分类/回归/聚类/降维/预处理/模型选择工具。 |
| 🆓 付费类 | 免费吗? | 完全开源免费(BSD),可商用。 |
| 🎯 API 类 | API 风格是什么? | 统一 API:所有算法遵循 fit(X,y)/predict(X)/transform(X) 接口。 |
| 🧩 算法类 | 支持哪些算法? | 分类(GBDT/随机森林/KNN/SVM/逻辑回归)、回归(GBDT/岭/Lasso)、聚类(k-Means/HDBSCAN)、降维(PCA/t-SNE/NMF)等。 |
| 🧮 底座类 | 基于哪些库? | NumPy、SciPy、matplotlib。 |
| ⚡ 性能类 | 核心代码什么语言? | C/Cython 优化,速度快。 |
| 🔢 版本类 | 当前版本? | v1.8.0(2025 年 12 月)。 |
🔍 八、替代方案与对比参考
1. 云端 AI 产品竞品对比分析
| 云AI工具 | 核心优势 | 相比 scikit-learn 短板 | 官网下载渠道网址 |
|---|---|---|---|
| 🧩 XGBoost | 梯度提升库,Kaggle 竞赛最好单模型,GBDT 业界标准 | 仅梯度提升单一算法族,无全套分类/回归/聚类/降维/预处理,无统一 API,需单独学习 | https://xgboost.readthedocs.io |
| 🧩 LightGBM | 微软梯度提升库,训练快内存低,GOSS/EFB 优化 | 仅 GBDT 单一算法族,无统一 ML 框架,无聚类/降维/预处理 | https://lightgbm.readthedocs.io |
| 🧩 PyTorch | 最流行深度学习框架,动态图灵活 | 非传统 ML 库(侧重深度神经网络),手动实现逻辑回归/随机森林等算法,无统一 API | https://pytorch.org |
| 🧪 statsmodels | 统计模型库,统计推断和假设检验强 | 侧重统计分析而非 ML 预测,无统一 API(无 fit/predict),运行分类/聚类等经典 ML 算法 | https://www.statsmodels.org |
| 🧩 Pandas | Python 数据分析库,数据操作+基础统计 | 无 ML 算法实现,无分类/回归/聚类/降维能力 | https://pandas.pydata.org |
| 🧩 scikit-learn | 统一 API+全 ML 算法族+预处理+模型选择+BSD | 最全面的传统 ML 库 | — |
2. 本地部署方案竞品对比分析
| 本地软件 | 核心优势 | 相比 scikit-learn 短板 | 官网下载渠道网址 |
|---|---|---|---|
| 🧩 XGBoost(本地版) | GBDT 工程实现最快 | 仅提升树算法 | https://xgboost.readthedocs.io |
| 🧩 LightGBM(本地版) | 微软 GBDT 实现 | 仅 GBDT | https://lightgbm.readthedocs.io |
| 🧩 CatBoost(本地) | 处理类别特征最优 | 仅梯度提升 | https://catboost.ai |
| 🧩 Imbalanced-learn | 不平衡数据集处理库 | 仅不平衡学习工具,无全面 ML 算法 | https://imbalanced-learn.org |
| 🧪 自建 Python 算法 | 完全自控 | 需从零实现全部算法,开发周期极长 | — |
3. 通用大模型能力横向评估
| 大模型 | 核心优势 | 相比 scikit-learn 短板 | 官网下载渠道网址 |
|---|---|---|---|
| 🔍 GPT-4o (OpenAI) | 多模态理解领先 | 无 ML 库能力 | https://chatgpt.com |
| 🔍 DeepSeek-R1 | 推理能力强 | 无 ML 库能力 | https://chat.deepseek.com |
4. 模型选型适配场景推荐指南
| 适用场景 | 推荐选型方案 | 选型说明 | 获取渠道网址 |
|---|---|---|---|
| 🧩 通用传统 ML 全流程 | scikit-learn | 统一 API+全算法+预处理+模型选择 | — |
| 🏆 Kaggle 高精度预测 | XGBoost/LightGBM | 梯度提升 Boosting 最强 | https://xgboost.readthedocs.io |
| 🤖 深度学习/神经网络 | PyTorch/TensorFlow | 深度神经网络 | https://pytorch.org |
| 🧪 统计推断和检验 | statsmodels | 统计建模和分析 | https://www.statsmodels.org |
| 💻 基础数据分析 | Pandas+sklearn | 数据分析+ML 预测 | https://pandas.pydata.org |
| 🎯 不平衡数据分类 | Imbalanced-learn | SMOTE 等采样技术 | https://imbalanced-learn.org |
5. 开源模型生态与安全下载渠道
| 渠道平台 | 官方网址 | 渠道核心优势与安全说明 | 适配场景与使用说明 |
|---|---|---|---|
| 🌐 GitHub(scikit-learn) | https://github.com/scikit-learn/scikit-learn | 官方仓库 | 源码、Issue、PR |
| 🖥️ PyPI | https://pypi.org/project/scikit-learn/ | Python 包仓库 | pip install scikit-learn |
| 📖 scikit-learn 文档 | https://scikit-learn.org | 官方文档 | 用户指南/API 参考/700+ 示例 |
| 📚 scikit-learn 示例 | https://scikit-learn.org/stable/auto_examples | 700+ 示例索引 | 学习各算法的最佳途径 |
| 🖥️ Conda Forge | https://anaconda.org/conda-forge/scikit-learn | conda 安装 | conda install -c conda-forge scikit-learn |
6. 开源替代方案与本地自建评估
| 开源方案名称 | 官方网址 | 核心能力说明 | 是否可本地部署 | 与 scikit-learn 对比优劣 |
|---|---|---|---|---|
| 🧩 XGBoost + LightGBM + CatBoost | xgboost.readthedocs.io | 三个独立 GBDT 库,竞赛性能最强 | ✅ 是 | 优势:GBDT 实现最优化,竞赛成绩最好。劣势:仅提升树/提升算法,无全分类/回归/聚类/降维/预处理一套菜单,无统一 API |
| 🧩 PyTorch/TF | pytorch.org | 深度学习框架 | ✅ 是 | 劣势:非传统 ML 库,逻辑回归/随机森林等需手动实现,学习成本高 |
| 🧪 statsmodels | statsmodels.org | 统计建模库 | ✅ 是 | 劣势:侧重统计推断,非 ML 预测,无统一 fit/predict API |
| 🧩 自建 Python 算法 | — | 从零实现 ML 算法 | ✅ 是 | 劣势:从零实现所有算法,代码量极大,效果无保证 |
| 🧩 Imbalanced-learn | imbalanced-learn.org | 不平衡数据处理 | ✅ 是 | 劣势:仅不平衡学习工具,与 scikit-learn 互补而非替代 |
| 🧩 scikit-learn | — | 统一 API+全算法+预处理+模型选择+BSD+C/Cython | ✅ 是 | 最全面的 Python 传统 ML 库 |
选型建议: scikit-learn 在「统一 API 设计(fit(X,y)/predict(X)/transform(X)——所有算法一致的接口范式,学习成本最低)+ 最完整的传统 ML 算法集(分类/回归/聚类/降维/预处理全部主流算法的工业级实现)+ 模型选择和评估工具(GridSearchCV/RandomizedSearchCV/cross_val_score/learning_curve 等,模型参数优化全流程)+ 预处理管线(StandardScaler/OneHotEncoder/CountVectorizer 等,数据准备标准化)+ NumPy/SciPy 原生集成(与 Python 数据科学生态无缝兼容)+ BSD 许可+C/Cython 高性能+700+ 示例和 70h 视频+社区治理成熟」的综合优势上,对于需要传统 ML 建模的数据科学家和工程师来说是标准选择。最直接的对比是深度学习框架(PyTorch/TF),两者定位不同:scikit-learn 覆盖传统机器学习全栈,统一 API 设计使其在各算法之间切换极为方便,适合中小规模数据上的 ML 任务;PyTorch 适合需要深度神经网络的复杂任务。对于需要 GPU 训练的深度学习场景,PyTorch 是标准选择。对于需要纯预测性能的比赛场景,XGBoost 等 Boosting 库表现突出。实际项目中常以 scikit-learn 做全流程 ML 数据预处理+基线模型+轻量快速原型验证,XGBoost 做最终性能优化,PyTorch 做深度学习部分。